
Исследование контента и успешности на платформе Netflix
Вводная часть:
Для своего проекта я решила выбрать тематику известную всем, ставшую максимально актуальной и увеличившую популярность- стриминговый сервис, а именно её один из самых известных представителей Netflix. С прошедшей в прошлом пандемии данный тип сервисов стал очень популярен и сейчас имеет огромное влияние в жизни большинства людей. На современных стриминговых сервисах со временем сильно расширяется ассортимент разного плана картин: кино, сериалы, мультипликация, аниме и т. д. Каждый человек может найти себе что-то под вкус и настроение на каждый день.
Визуализация
Для визуализации работы были выбраны цвета логотипов 2-х фигурирующих ресурсов- это IMDB и Netflix.
Выбор данных
Исследование в работе было начато с выбора датасета на рекомендованном ресурсе kaggle.com.
Цель исследования
Целью моей работы является сравнительный анализ как качества картин, так и анализ успешности картины по ее разным признакам и факторам. Причиной этому стало то, что данный сервис является одним из самых популярных в своей сфере.
Обработка данных:
Датасет содержит в себе метаданные о продуктах платформы Netflix с их оценками портала IMDB. После загрузки датасета в нашу среду: Сollab была произведена очистка данных. Был отфильтрован контент с менее чем 100 голосами на IMDB, были удалены строки с пропуском в ключевых колонках, преобразовали год в целое число для группировок и графиков. Добавление полезных признаков: Логарифм голосов — нормализует сильно скошенные данные (голоса варьируются от сотен до миллионов), делая корреляции и визуализации более интерпретируемыми. Функция categorize_runtime: Создаёт категорию продолжительности (runtime_category) на основе типа контента.
Статистические методы в работе:
1 Описательная статистика- базовый метод для суммирования данных: расчёт мер центральной тенденции (среднее, медиана), разброса (стандартное отклонение, дисперсия), экстремумов (мин/макс) и распределений (квантили). 2 Корреляция Пирсона — мера линейной зависимости между двумя числовыми переменными (от -1 до 1: положительная/отрицательная корреляция, 0 — отсутствие). 3 Линейная регрессия — модель для предсказания зависимости одной переменной от другой. 4 Групповые статистики и агрегация — разделение данных на группы и расчёт статистик (средние, подсчёты) для сравнения. 5 Нормализация и трансформация данных — преобразование данных для улучшения распределения 6 Биннинг — разделение непрерывной переменной на категории (бины) для упрощения анализа.
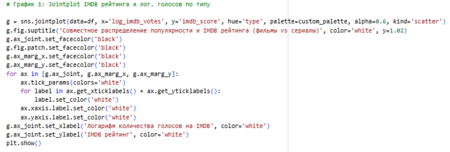
1 Jointplot: Выбран для изучения совместного распределения популярности и рейтинга, с разделением по типу (фильмы/сериалы). Причиной выбора стало то, что комбинирует scatter (корреляцию) и гистограммы (распределения), показывая, как успех коррелирует с вовлечённостью аудитории.
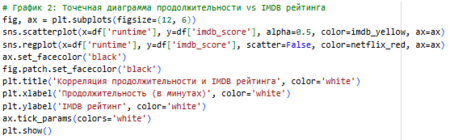
2 Точечная диаграмма Scatterplot с регрессией Выбрана для анализа корреляции продолжительности и рейтинга. Scatter показывает индивидуальные точки (разброс), а регрессия — тренд.
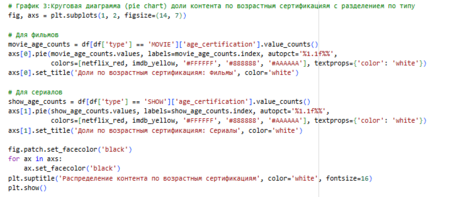
3 Круговая диаграмма: Pie chart идеален для пропорций и долей в категориальных данных, когда нужно показать, как распределяется общее целое. Возрастная сертификация отражает таргетинг аудитории — ключевой фактор коммерческого успеха.
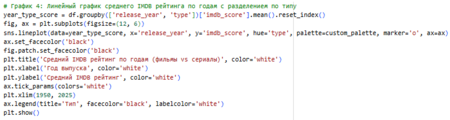
4 Линейный график: Линейный график — стандарт для временных рядов и трендов.
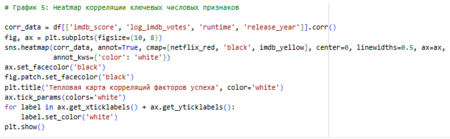
5 Heatmap: Heatmap — лучший способ визуализировать матрицу корреляций (много переменных одновременно). Цвет и аннотации дают мгновенное понимание силы/направления связей. Суммирует взаимосвязи факторов, завершает анализ, давая обзор всех зависимостей.
Итоги:
Анализ датасета был сосредоточен на факторах успеха контента, где основным индикатором качества выступал IMDB-рейтинг (средняя оценка зрителей), а популярности — количество голосов. Дополнительно учитывались продолжительность, год выпуска и возрастные сертификации как косвенные метрики вовлечённости и охвата аудитории. Распределение IMDB-рейтингов близко к нормальному со средним около 6.3–6.5. Высокие оценки (8+) встречаются реже, особенно среди недавнего контента. Это указывает на стратегию платформы: массовое производство «средне-хорошего» контента для широкой аудитории, а не фокус на шедеврах. Слабая связь между популярностью и качеством. Линейная регрессия показала слабый отрицательный тренд — чем длиннее фильм или эпизод, тем ниже средняя оценка.



