
[1] Концепция
Основная идея проекта заключалась в обучении модели на собственном персонаже, чтобы в дальнейшем генерировать изображения, сохрающие его узнаваемость. В качестве референса я взяла персонажа, разработанного на 2-м курсе.
Я стремилась к тому, чтобы модель не просто воспроизводила исходные изображения, а могла генерировать новые вариации персонажа. То есть результат должен был сохранять стиль и особенности исходника, но при этом допускать разнообразие в позах, ракурсах и общем виде изображения.
[2] Датабаза

В качестве датабазы я использовала собственную 3D-модель персонажа. Датасет включал рендеры с разных ракурсов: фронтального, бокового и в три четверти, а также более детализированные кадры с крупными планами.

У персонажа были характерные черты внешности, именно поэтому мне было интересно посмотреть как их сможет передать и скопировать нейросеть. В выборке присутствуют кадры с хорошо проработанной одеждой. Видны такие элементы, как корсет, ремни и дополнительные декоративные мелочи, что позволило модели лучше усвоить структуру костюма и корректно воспроизводить его при генерации.
[3] Обучение модели
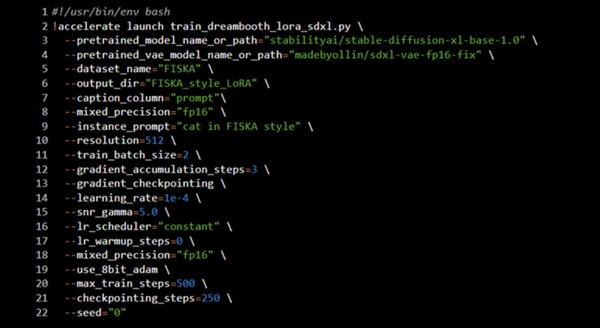
Сначала я настроила рабочую среду в Google Colab: подключила GPU и установила нужные библиотеки (diffusers, transformers и др.).
Далее загрузила свои изображения в папку и проверила, что они корректно открываются. После этого с помощью модели BLIP сгенерировала подписи к каждому изображению и добавила к ним указание моего стиля. Все данные сохранила в файл metadata.jsonl.
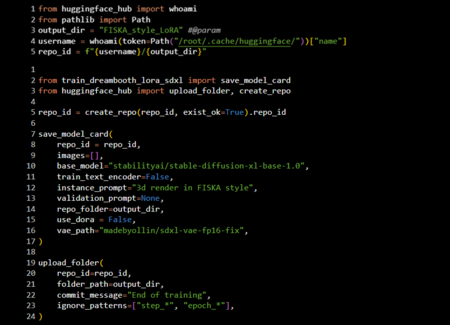
Затем очистила память и настроила accelerate, а также вошла в Hugging Face, чтобы потом сохранить модель.
Обучение проводилось с использованием DreamBooth LoRA на базе Stable Diffusion XL. Я задала основные параметры (разрешение, шаги обучения и т. д.) и запустила тренировку.
После окончания обучения модель сохранилась, и я загрузила её на Hugging Face.
После обучения я сравнила полученные изображения с исходным датасетом. В целом видно, что модель хорошо запомнила внешний вид персонажа и его основные детали.
В генерациях сохраняется: форма головы, большие уши, причёска и тараканьи усики. Это говорит о том, что модель смогла воспроизвести ключевые элементы.
[4] Итоговая серия
prompt [3d render in FISKA style, a girl in a room with a painting on the wall]
Вначале возникла проблема с отростками. На плечах они часто генерировались в избыточном количестве. Это связано с тем, что модель использовала слово «deer» , из-за чего она воспринимала их как рога и добавляла слишком активно.
prompt [3d render cute girl in FISKA style]
Интересно, что модель способна генерировать новые позы и ракурсы, которых и близко не было в датасете. При этом сохранялось изначальное «киношное» освещение.
prompt [3d render in FISKA style, a woman in a room, painting on wall, cinematic lighting, stylized]
Очень хорошо передаётся цветовая палитра — в изображениях повторяются зелёные и коричневые оттенки, в том числе текстуры остаются приближенными к оригиналу. Но больше всего порадовала одежда, так как практически во всех случаях она генерировалась корректно.
prompt [3d render in FISKA style, a woman in a green dress and brown boots]
Сильно зависит результат и от формулировки промпта. Например, использование слова «woman» давало более реалистичный и „серьёзный“ образ, тогда как „girl» делало персонажа более стилизованным, поэтому для большего попадания в референс вносились корректировки в промпт.
prompt [3d render in FISKA style, a woman in a green and brown outfit]
По итогу, для лучшего попадания в референс нужно было прописать несколько условий:
- «Girl», чтобы получить мягкие черты лица.
- «Green outfit», это сохраняло одежду и детали.
- «Cinematic light» и «In a room with a painting on the wall». Эти словосочетания делали картинку интереснее, и как раз благодаря ним вышли нестандартные позы и ракурсы, которые мне больше всего понравились.
prompt [3d render in FISKA style, same woman character, crying, red hair, green outfit, asymmetrical arms]
Вывод
Таким образом, модель справилась с ранее поставленной задачей и смогла передать основные особенности персонажа. Конечно, не все изображения получались одинаково удачными: где-то появлялись лишние детали, а где-то нарушалась анатомия. Но при этом в лучших примерах сохраняются силуэт, цветовая гамма и общая узнаваемость.
Также видно, что модель не только повторяет исходные изображения, но и генерирует новые варианты с разными позами и деталями. Это говорит о том, что она смогла усвоила стиль персонажа. Особенно полезно это оказалось при работе с одеждой.
Результат получился удачным, и такие генерации можно использовать для поиска идей и быстрых набросков.
Использованные ресурсы
Google Colab — использовался как основная среда для обучения модели и генерации изображений благодаря доступу к GPU https://colab.research.google.com
Gemini 3 — применялась для анализа, генерации идей и решения отдельных задач в процессе работы
Hugging Face — использовалась для размещения и публикации обученной LoRA-модели, а также для её последующего применения: https://huggingface.co
ChatGPT — задействовался в процессе разработки для отладки кода, настройки окружения и повышения эффективности обучения модели: https://chat.openai.com



