
Тильман Рименшнейдер (1460–1531) — скульптор южной Германии конца XV века. В его творчестве смешались готические и ренессансные черты, соединились экспрессия и грубоватая простота, глубокая внутренняя значимость человеческих образов и хрупкая изысканность готической орнаментики.
Концепция проекта строится вокруг переноса пластического языка скульптуры в цифровую генеративную среду. В качестве основы выбран художественный стиль Тильман Рименшнейдер — мастера, в чьих работах сочетаются готическая выразительность и зарождающиеся ренессансные принципы формы.
Его скульптуры характеризуются вниманием к внутреннему состоянию персонажей, подчеркнутой эмоциональностью, а также особой работой с материалом: фактура дерева, мягкость складок драпировок и детализированная орнаментика создают ощущение хрупкости и одухотворённости образов. При этом формы остаются несколько условными и обобщёнными, что усиливает их символическую значимость.
В рамках проекта предполагается обучить генеративную модель на корпусе изображений скульптур Рименшнейдера, чтобы она смогла воспроизводить характерные особенности его стиля: пластическую выразительность, драматургию жестов, структуру складок и баланс между реализмом и условностью.
Особое внимание уделяется тому, как нейросеть интерпретирует трёхмерную скульптурную форму в формате двумерной генерации: передаёт ли она ощущение объёма, материала и светотеневой моделировки, а также сохраняет ли эмоциональную насыщенность образов.
Цель проекта — оценить, насколько успешно генеративная модель способна анализировать и воспроизводить сложный художественный стиль, сформированный в другой медиальной среде (скульптура), и выявить границы её возможностей при работе с пластикой, фактурой и выразительной формой.

Обучение
На первом этапе изображения скульптур Тильман Рименшнейдер были загружены в среду Google Colab, где из них был сформирован обучающий датасет. В него вошли работы, отражающие ключевые особенности мастера: религиозные образы, выразительные складки драпировок и характерную пластику форм.
Далее для каждого изображения автоматически создавались текстовые описания с помощью модели BLIP. Это позволило связать визуальные признаки — фактуру дерева, светотеневую моделировку, анатомические особенности и эмоциональную выразительность — с их смысловым содержанием.
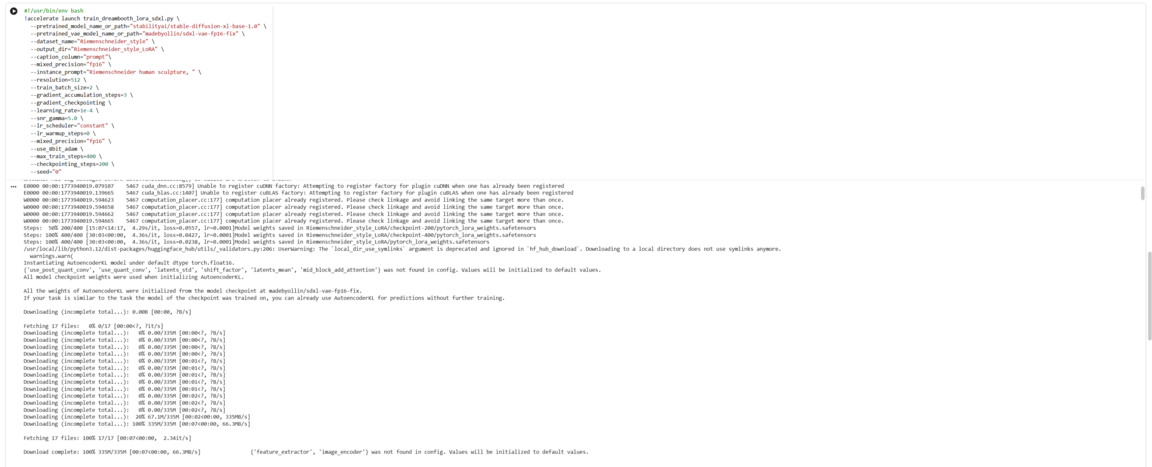
После этого был запущен процесс обучения. В качестве основы использовалась модель Stable Diffusion XL, а её дообучение под конкретный стиль осуществлялось с применением DreamBooth и LoRA. Обучение проводилось через специальный скрипт.
Параметры обучения настраивались с учётом ограничений Google Colab, чтобы добиться устойчивой работы модели и при этом сохранить качество передачи пластики, объёма и деталей.
По завершении обучения полученные веса были интегрированы обратно в базовую модель через библиотеку Diffusers, что позволило использовать сформированный стиль при генерации новых изображений.
Итоговые изображения


«Riemenschneider human sculpture, religious figure holding book, delicate carving, elongated proportions, muted tones»
«Riemenschneider human sculpture, standing wooden saint, intricate folds, expressive face, late gothic style»


«Riemenschneider human sculpture, carved wooden saint, soft facial expression, flowing drapery, gothic realism»
«Riemenschneider human sculpture, wooden figure with detailed robes, calm sorrowful face, natural wood texture»


«Riemenschneider human sculpture, carved wooden saint, soft facial expression, flowing drapery, gothic realism»
«Riemenschneider woman sculpture, mother with a long scarf»
Результаты генерации показали, что модель в целом успешно справилась с передачей художественного языка Тильман Рименшнейдер. В сгенерированных изображениях считываются характерные черты его стиля: пластическая выразительность, внимание к драпировкам, мягкая светотеневая моделировка и общее ощущение одухотворённости образов.
При этом были зафиксированы отдельные технические недостатки. В некоторых случаях наблюдаются искажения анатомии, неточности в пропорциях и недостаточная чёткость деталей, что влияет на общее качество исполнения и снижает убедительность формы.
Тем не менее, несмотря на эти ограничения, модель демонстрирует устойчивую способность воспроизводить стилистические особенности скульптора. В целом можно говорить о успешной передаче художественного стиля, с перспективой дальнейшего улучшения точности и детализации.
Генеративная модель в проекте
В проекте использовался набор ИИ-инструментов, объединённых в единый пайплайн. Основой служила Stable Diffusion XL (SDXL) — диффузионная модель, генерирующая изображения по текстовым описаниям. Для адаптации под конкретный стиль применялся DreamBooth, позволяющий дообучить модель на небольшом датасете и закрепить визуальные особенности. Модель BLIP использовалась для автоматического создания текстовых описаний изображений, улучшая связь между визуальными данными и промптами. Дополнительно применялась ChatGPT для генерации и доработки текстовых запросов. На уровне кода все компоненты объединялись через Python и библиотеку Diffusers: происходила загрузка данных, генерация подписей, настройка параметров обучения и запуск тренировки с последующим подключением обученных весов для генерации изображений.
https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0 https://arxiv.org/abs/2208.12242 https://huggingface.co/Salesforce/blip-image-captioning-base https://chat.openai.com



